Wie messen Technologieunternehmen den Einfluss von KI auf die Softwareentwicklung?
(newsletter.pragmaticengineer.com)- Angesichts der breiten Einführung von AI-Coding-Tools und steigender Kosten fassen bekannte Technologieunternehmen die Methoden zur Quantifizierung des tatsächlichen Nutzens von AI in einem mehrschichtigen Kennzahlensystem zusammen
- Im Kern steht ein hybrider Ansatz, bei dem sowohl bestehende grundlegende Engineering-Metriken (z. B. PR-Durchsatz, Change Failure Rate) als auch AI-spezifische Kennzahlen (z. B. AI-Nutzungsrate, Zeitersparnis, CSAT) gemeinsam verfolgt werden
- Betont wird eine experimentelle Denkweise, die Trends und Korrelationen durch Aufschlüsselung nach dem AI-Nutzungsniveau auf Team-, Einzel- und Kohortenebene sowie durch Vorher-Nachher-Vergleiche ableitet
- Erforderlich ist ein ausgewogenes Design, das Qualität, Wartbarkeit und Developer Experience fortlaufend zusammen mit Geschwindigkeitsmetriken überwacht, um wachsende technische Schulden und negative Nebenwirkungen kurzfristiger Vorteile zu vermeiden
- Langfristig wird eine Ausweitung der Messung auf Agenten-Telemetrie aus der Ferne und nicht codierende Arbeitsbereiche erwartet; letztlich läuft die Frage darauf hinaus, ob AI das, was bereits wichtig ist (Qualität, Time-to-Market, Developer Experience), tatsächlich verbessert
AI-Impact-Diskurs und Messlücke
- Wie man etwa auf LinkedIn häufig sieht, gibt es unzählige Behauptungen, dass AI die Art verändert, wie Unternehmen Software entwickeln
- Berichte über große Mengen AI-generierten Codes, die tatsächlich als Production-Code ausgerollt werden, reißen nicht ab, etwa bei Google 25% und Microsoft 30%
- Während einige Gründer behaupten, AI könne Junior Engineers ersetzen, zeigt die METR-Studie die Möglichkeit von verzerrter Zeitwahrnehmung und sinkender Produktivität
- Die Medien reduzieren den AI-Impact oft vereinfacht auf „wie viel Code geschrieben wurde“, doch dadurch steht die Branche vor dem Risiko, technische Schulden in beispiellosem Ausmaß anzuhäufen
- Obwohl Einigkeit darüber bestand, dass LOC (Zeilenanzahl) als Produktivitätsmetrik ungeeignet ist, erlebt sie wegen ihrer leichten Messbarkeit ein Comeback, wodurch wesentliche Werte wie Qualität, Innovation, Time-to-Market und Zuverlässigkeit in den Hintergrund geraten
- Viele Engineering-Führungskräfte treffen derzeit wichtige Entscheidungen über AI-Tools, ohne klar zu wissen, was funktioniert und was nicht
- Laut dem LeadDev 2025 AI Impact Report nennen 60 % der Führungskräfte das „Fehlen klarer Kennzahlen“ als größte Herausforderung
- Führungskräfte vor Ort zeigen sich frustriert zwischen Ergebnisdruck und auf LOC fixierten Führungsetagen, und die Lücke zwischen benötigten Informationen und tatsächlicher Messung wird immer größer
- Der Autor erforscht seit mehr als zehn Jahren Developer-Tools und berät seit 2021 zu Produktivitätssteigerung und Messung des AI-Impacts
- Seit dem Einstieg als DX CTO hat er mit Hunderten Unternehmen zusammengearbeitet und Analysen zu DevEx, Effizienz und AI-Einfluss geleitet
- Anfang 2025 verfasste er auf Basis von Daten aus mehr als 400 Unternehmen das AI Measurement Framework mit
- Dabei handelt es sich um einen empfohlenen Satz von Kennzahlen für die Einführung von AI und die Messung ihrer Auswirkungen, aufgebaut auf Feldforschung und Datenanalyse
- In diesem Beitrag wird betrachtet, wie 18 Tech-Unternehmen den AI-Impact tatsächlich messen, und es werden
- konkrete Kennzahlenbeispiele von Google, GitHub, Microsoft und anderen
- Anwendungsweisen, um zu erkennen, was wirksam ist
- Methoden zur Messung des AI-Impacts
- sowie Definitionen und Leitfäden zu AI-Impact-Kennzahlen vorgestellt
1. Tatsächliche Messgrößen in 18 Unternehmen
- Beispiele aus 18 Unternehmen wie Google, GitHub, Microsoft, Dropbox, Monzo, Atlassian, Adyen, Booking.com und Grammarly werden als Bild geteilt
- Die Unternehmen verfolgen unterschiedliche Ansätze, konzentrieren sich aber gemeinsam auf einige zentrale Kennzahlengruppen
-
1. Nutzungskennzahlen (Adoption & Usage)
- DAU/WAU/MAU: Fast alle Unternehmen verfolgen die täglich, wöchentlich und monatlich aktiven Nutzer von AI-Tools
- Nutzungsintensität/Nutzungsereignisse: Google, eBay und andere differenzieren bis hin zu Codeerstellung, Chat-Antworten und agentic actions
- AI tool CSAT: Viele Unternehmen wie Dropbox, Webflow und Grammarly kombinieren dies mit Zufriedenheitsumfragen
-
2. Produktivitätskennzahlen (Throughput & Time Savings)
- PR-Durchsatz (PR throughput): Wird von vielen Unternehmen wie GitHub, Dropbox, Webflow und CircleCI gemeinsam verfolgt
- Zeitersparnis (Time savings): Messung der wöchentlich eingesparten Zeit pro Engineer (Dropbox, Monzo, Toast, Xero usw.)
- PR Cycle Time: Im Einsatz bei Microsoft, CircleCI, Xero, Grammarly und anderen
-
3. Qualitäts-/Stabilitätskennzahlen (Quality & Reliability)
- Change Failure Rate: Die häufigste Qualitätsmetrik bei GitHub, Dropbox, Adyen, Booking.com, Webflow und anderen
- Wahrgenommene Wartbarkeit/Codequalität: Bewertung bei GitHub, Adyen, CircleCI und anderen in Verbindung mit DevEx
- Bugs/Revert-Rate: Glassdoor (Anzahl der Bugs), Toast (PR revert rate)
-
4. Kennzahlen zur Developer Experience (Developer Experience)
- Developer-Zufriedenheit/Umfragen (DevEx, DXI): Im Einsatz bei Atlassian, Webflow, CarGurus, Vanguard und anderen
- Bad Developer Days (BDD): Microsoft misst Reibung auf originelle Weise mit dem Konzept „schlechter Entwicklertag“
- Kognitive Last und Developer Friction: Bei Google, eBay und anderen
-
5. Kosten- und Investitionskennzahlen (Spend & ROI)
- AI-Ausgaben (gesamt & pro Entwickler): Einige Unternehmen verfolgen die Kosten, etwa in Fällen von Dropbox, Grammarly und Shopify
- Capacity worked (Auslastung): Glassdoor misst, wie stark das Tool im Verhältnis zu seinem maximalen Potenzial genutzt wurde
-
6. Kennzahlen zu Innovation/Experimenten (Innovation & Experimentation)
- Innovation ratio / velocity: GitHub, Microsoft, Webflow und andere fassen Innovationstempo in Kennzahlen
- Anzahl der A/B-Tests: Glassdoor nutzt die monatliche Zahl der A/B-Tests als zentrale Kennzahl
- Ergebniskennzahlen wie Zeitersparnis, PR-Durchsatz, Change Failure Rate, aktive Nutzer und Innovationsrate werden parallel zu Kennzahlen des Nutzungsverhaltens verfolgt
- Je nach Prioritäten der Organisation und Produktkontext unterscheidet sich die Zusammenstellung der Kennzahlen; eine einzige universelle Kennzahl gibt es nicht
2. Robuste Grundlage: Der Kern der Messung von AI-Impact
- Dass Code mit KI geschrieben wird, ändert nichts an den Maßstäben für gute Software. Qualität, Wartbarkeit und Geschwindigkeit bleiben entscheidend
- Daher bleiben bestehende Kennzahlen wie Change Failure Rate, PR Throughput, PR Cycle Time und Developer Experience (DevEx) weiterhin wichtig
- Völlig neue Kennzahlen sind nicht nötig
- Die wichtige Frage lautet: „Macht KI die Dinge, die schon bisher wichtig waren, tatsächlich besser?“
- Wer bei oberflächlichen Kennzahlen wie LOC oder Akzeptanzrate stehen bleibt, kann den Einfluss von KI nicht richtig erfassen
- Um genau zu verstehen, was bei der KI-Nutzung passiert, sind neue Zielmetriken nötig
- Sie zeigen, wo, in welchem Umfang und auf welche Weise KI eingesetzt wird, und können für Entscheidungen zu Budget, Tool-Rollout, Sicherheit und Compliance genutzt werden
- KI-Metriken zeigen zum Beispiel:
- Wie viele Entwickler und welche Typen von Entwicklern setzen KI-Tools ein?
- Wie viele Aufgaben und welche Arten von Aufgaben werden von KI beeinflusst?
- Wie hoch sind die Kosten?
- Zentrale Engineering-Kennzahlen zeigen zum Beispiel:
- Ob Teams schneller shippen
- Ob Qualität und Zuverlässigkeit steigen oder sinken
- Ob die Wartbarkeit des Codes abnimmt
- Ob KI-Tools Reibung im Entwickler-Workflow verringern
-
Am Beispiel Dropbox
- KI-Kennzahlen
- DAU/WAU (täglich bzw. wöchentlich aktive Nutzer)
- AI tool CSAT (Zufriedenheit)
- Zeitersparnis pro Engineer
- KI-Ausgaben
- Kernkennzahlen (mit dem Core 4 Framework)
- Change Failure Rate
- PR Throughput
- Ergebnisse
- Wöchentliche regelmäßige KI-Nutzer = 90 % aller Engineers (höher als der Branchendurchschnitt von 50 %)
- Regelmäßige KI-Nutzer verzeichneten 20 % mehr PR-Merges + eine niedrigere Change Failure Rate
- Entscheidend ist nicht die Adoptionsrate an sich, sondern ob sie tatsächlich zu besseren Ergebnissen auf Organisations-, Team- und Individualebene beiträgt
- KI-Kennzahlen
3. Aufschlüsselung von Kennzahlen nach dem Ausmaß der KI-Nutzung
- Um zu verstehen, wie KI die Arbeitsweise von Entwicklern verändert, werden verschiedene Vergleichsanalysen durchgeführt
- Vergleich von KI-Nutzern und Nichtnutzern
- Vergleich zentraler Engineering-Kennzahlen vor und nach der Einführung von KI-Tools
- Beobachtung von Veränderungen nach der KI-Einführung durch Verfolgung derselben Nutzergruppe (cohort analysis)
- Durch die Segmentierung der Daten (slicing & dicing) werden Muster sichtbar
- Analyse nach Merkmalen wie Rolle, Betriebszugehörigkeit, Region oder primärer Sprache
- Beispiel: Bei Juniors steigt die Zahl der PR-Erstellungen, während sich Seniors wegen eines höheren Review-Anteils verlangsamen
- So lassen sich Gruppen mit zusätzlichem Schulungs- und Unterstützungsbedarf sowie Gruppen mit besonders hohem Nutzen durch KI identifizieren
- Beispiel Webflow
- In der Gruppe mit mehr als drei Jahren Betriebszugehörigkeit war der Zeitspareffekt durch KI am größten
- Beim Einsatz von Tools wie Cursor und Augment Code stieg der PR Throughput um 20 % (Vergleich KI-Nutzer vs. Nichtnutzer)
- Die Notwendigkeit einer belastbaren Baseline
- Für Organisationen ohne Grundlage bei Kennzahlen zur Entwicklerproduktivität ist es schwierig, den KI-Einfluss zu messen
- Mit dem Core 4 Framework (genutzt von Dropbox, Adyen, Booking.com u. a.) lässt sich schnell eine Basislinie schaffen
- Siehe Vorlage und Leitfaden
- Durch die gemeinsame Nutzung von Systemdaten, Experience-Sampling-Daten und regelmäßigen Umfragen werden belastbare Vergleiche möglich
- Kontinuierliches Tracking und experimentelles Denken sind entscheidend
- Eine einmalige Messung ist wenig aussagekräftig; Trends und Muster müssen durch Zeitreihenverfolgung erkannt werden
- Gemeinsamkeit erfolgreicher Unternehmen: Sie setzen konkrete Ziele und prüfen Hypothesen anhand von Daten
- Dabei verlassen sie sich nicht blind auf Daten, sondern behalten eine zielorientierte experimentelle Denkweise bei
4. Wachsamkeit bei Wartbarkeit, Qualität und Developer Experience
- KI-gestützte Entwicklung ist weiterhin ein neues Feld
- Es fehlen noch Daten, die die langfristigen Auswirkungen auf Codequalität und Wartbarkeit belegen
- Die Balance zwischen kurzfristigen Geschwindigkeitsgewinnen und dem Risiko langfristiger technischer Schulden ist die zentrale Herausforderung
- Es sollten auch gegenläufige Kennzahlen gemeinsam verfolgt werden
- Die meisten Unternehmen verfolgen Change Failure Rate und PR Throughput gleichzeitig
- Wenn die Geschwindigkeit steigt, aber die Qualität sinkt, ist das ein sofortiges Warnsignal
- Zusätzliche Kennzahlen zur Überwachung von Qualität und Wartbarkeit
- Change confidence: das Vertrauen der Entwickler in die Stabilität des Codes beim Deployment
- Code maintainability: wie leicht sich Code verstehen und ändern lässt
- Perception of quality: die Wahrnehmung der Entwickler hinsichtlich Codequalität und Praktiken auf Teamebene
- Systemkennzahlen und selbstberichtete Kennzahlen müssen kombiniert werden
- Systemdaten: PR Throughput, Deployment-Frequenz usw.
- Selbstberichtete Daten: Änderungsvertrauen, Wartbarkeit usw. → ein zentrales Signal, um langfristige negative Auswirkungen zu verhindern
- Regelmäßige Umfragen zur Developer Experience (DevEx) werden empfohlen
- Mit dem Beispiel für eine Umfrage lässt sich der Zusammenhang zwischen Qualität, Wartbarkeit und KI-Nutzung verfolgen
- Auch unstrukturiertes Feedback ist nützlich, um bestehende Probleme zu erkennen und Lösungen zu diskutieren
- Was Developer Experience (DevEx) tatsächlich bedeutet
- Nicht Benefits wie „Tischtennis und Bier“, sondern die Beseitigung von Reibung im gesamten Entwicklungsprozess
- Ziel ist Effizienz über den gesamten Ablauf hinweg: Planung → Entwicklung → Test → Deployment → Betrieb
- KI-Tools können die Reibung beim Schreiben von Code und beim Testen verringern, bergen aber das Risiko, neue Reibung bei Reviews, Incident Response und Wartung hinzuzufügen
- Praxis-Insight (CircleCI, Shelly Stuart)
- Output-Kennzahlen (PR Throughput) zeigen, was passiert, aber die Zufriedenheit der Entwickler zeigt die Nachhaltigkeit
- Die Einführung von KI kann anfangs Unannehmlichkeiten verursachen; deshalb ist das Tracking der Zufriedenheit ein zentrales Werkzeug, um kurzfristige Reibung von langfristigem Nutzen zu unterscheiden
- 75 % der Unternehmen verfolgen zusätzlich CSAT/Zufriedenheit mit KI-Tools → der Fokus liegt stärker auf einer nachhaltigen Entwicklungskultur als nur auf Geschwindigkeit
5. Einzigartige Kennzahlen und interessante Trends
- Microsoft: Bad Developer Day (BDD)
- Ein Konzept zur Echtzeitmessung von Reibung und Ermüdung im Arbeitsalltag
- Faktoren, die einen Tag schlecht machen, sind etwa Incident Response und Compliance-Bearbeitung, die Wechselkosten zwischen Meetings und E-Mails sowie die für Work-Management-Systeme aufgewendete Zeit
- In Kombination mit PR-Aktivitäten (ein Proxy für Coding-Zeit) wird ein Tag als gut bewertet, wenn trotz einiger geringwertiger Aufgaben eine gewisse Zeit fürs Coding gesichert werden konnte
- Ziel: zu prüfen, ob AI-Tools die Häufigkeit und Schwere von BDD verringern
- Glassdoor: Experimente und Messung der Tool-Nutzungsrate
- Über die monatliche Anzahl von A/B-Tests wird verfolgt, ob AI das Innovationstempo und die Geschwindigkeit von Experimenten erhöht
- Parallel dazu wird eine Strategie verfolgt, Power User zu internen AI-Evangelisten aufzubauen
- Capacity worked (Nutzungsgrad): Gemessen wird die tatsächliche Nutzung im Verhältnis zur potenziellen Nutzung eines Tools, um den Sättigungspunkt der Einführung und mögliche Umschichtungen im Budget zu beurteilen
- Rückgang der Acceptance Rate
- Früher war sie eine zentrale AI-Kennzahl, ihr Blickwinkel ist jedoch zu eng, da sie nur den Moment der Annahme eines Vorschlags betrachtet
- Wartbarkeit, Bug-Entstehung, Code-Reverts und das subjektive Produktivitätsempfinden von Entwicklern werden darin nicht erfasst
- Heute wird sie meist nicht mehr als Top-Level-Metrik verwendet, es gibt aber Ausnahmen:
- GitHub: Nutzung zur Verbesserung von Copilot und für Produktentscheidungen
- T-Mobile: Abschätzung, in welchem Maß AI-Code tatsächlich in die Produktion gelangt
- Atlassian: Verwendung als ergänzende Kennzahl für Entwicklerzufriedenheit und Vorschlagsqualität
- Kosten- und Investitionsanalyse
- Die meisten Unternehmen verfolgen die Nutzungskosten nicht aktiv, um keine abschreckende Wirkung auf Entwickler zu erzeugen
- Shopify setzt mit dem AI Leaderboard darauf, Entwickler mit hohem Token-Verbrauch zu würdigen
- ICONIQ 2025 State of AI Report: Es wird erwartet, dass sich das Budget für AI-Produktivität in Unternehmen 2025 gegenüber 2024 verdoppelt
- Teilweise erfolgt der Wandel dadurch, dass Recruiting-Budgets gekürzt und AI-Tool-Budgets entsprechend aufgestockt werden
- Fehlende Agenten-Telemetrie
- Derzeit wird hier kaum gemessen, eine Einführung innerhalb der nächsten 12 Monate gilt jedoch als wahrscheinlich
- Mit der Verbreitung autonomer Agent-Workflows wächst der Bedarf, Verhalten, Genauigkeit und Regressionsraten zu messen
- Mangelnde Messung nicht codierbezogener Aktivitäten
- Der Fokus liegt derzeit auf Unterstützung beim Schreiben von Code; Dinge wie Planungs-Sessions mit ChatGPT oder die Bearbeitung von Jira-Issues sind kaum einbezogen
- 2026 dürfte sich der AI-Einsatz auf alle Phasen des SDLC ausweiten, entsprechend muss sich auch die Messung weiterentwickeln
- Konkrete Aktivitäten wie Code Review oder Schwachstellenprüfungen sind leicht messbar, abstraktere Aufgaben dagegen schwer
- Es wird erwartet, dass sich der Einsatz selbstberichteter Messungen („Wie viel Zeit haben Sie diese Woche durch AI gespart?“) ausweitet
6. Wie sollte der AI-Impact gemessen werden?
- AI Measurement Framework
- Gemeinsam mit Abi Noda, Co-Autor des DevEx Framework, entwickelt
- Basierend auf Praxidaten aus über 400 Unternehmen und Forschung zur Entwicklerproduktivität aus den vergangenen gut zehn Jahren erstellt
- Bewertet durch die Kombination von AI-Metriken und Core Metrics gemeinsam Geschwindigkeit, Qualität, Wartbarkeit und Developer Experience (DevEx)
- Eine einzelne Kennzahl (z. B. der Anteil von AI-generiertem Code) eignet sich für Headline-Zahlen, ist aber kein ausreichendes Mittel zur Erfolgsmessung
- Qualitative + quantitative Daten müssen gemeinsam genutzt werden
- Nur wenn sowohl Systemmetriken (PR-Durchsatz, DAU/WAU, Deployment-Frequenz usw.) als auch selbstberichtete Kennzahlen (CSAT, Zeitersparnis, wahrgenommene Wartbarkeit usw.) erhoben werden, ist ein mehrdimensionales Verständnis möglich
- Viele Unternehmen nutzen DX zur Datenerhebung und Visualisierung, der Aufbau eigener Systeme ist ebenfalls möglich
- Methoden der Datenerhebung
- Systemdaten (quantitativ): Management-APIs von AI-Tools (Nutzung, Ausgaben, Tokens, Acceptance Rate) plus Kennzahlen aus SCM, JIRA, CI/CD, Builds und Incident Management
- Regelmäßige Umfragen (qualitativ): Quartals- oder Halbjahresumfragen helfen, langfristige Trends bei DevEx, Zufriedenheit, Vertrauen in Änderungen und Wartbarkeit zu erkennen, die sich über Systemmetriken schwer erfassen lassen
- Experience Sampling (qualitativ): kurze Fragen direkt im Workflow einblenden (z. B. direkt nach dem Einreichen eines PR: „Haben Sie AI verwendet?“, „War dieser Code leicht verständlich?“)
- Prioritäten bei der Umsetzung
- Regelmäßige Umfragen sind der schnellste Einstiegspunkt: Erste Daten lassen sich innerhalb von 1 bis 2 Wochen gewinnen
- So wie beim Aufhängen eines Vorhangs und beim Start einer Rakete unterschiedliche Präzision nötig ist, sind auch Engineering-Entscheidungen schon mit einer Genauigkeit sinnvoll, die ausreichend Richtung vorgibt
- Werden anschließend weitere Methoden der Datenerhebung kombiniert und gegengeprüft, steigt die Verlässlichkeit
- Zusätzliche Ressourcen
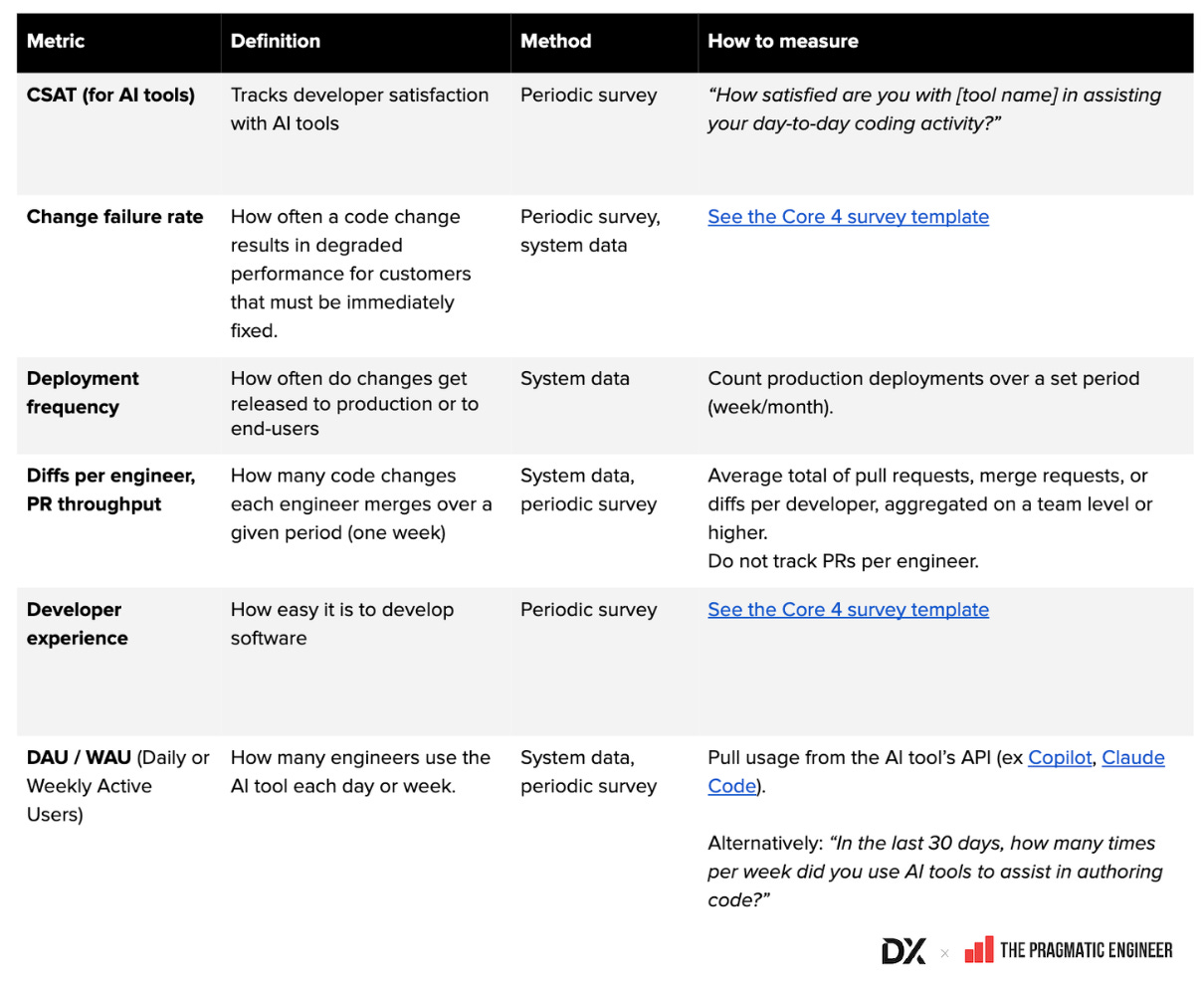
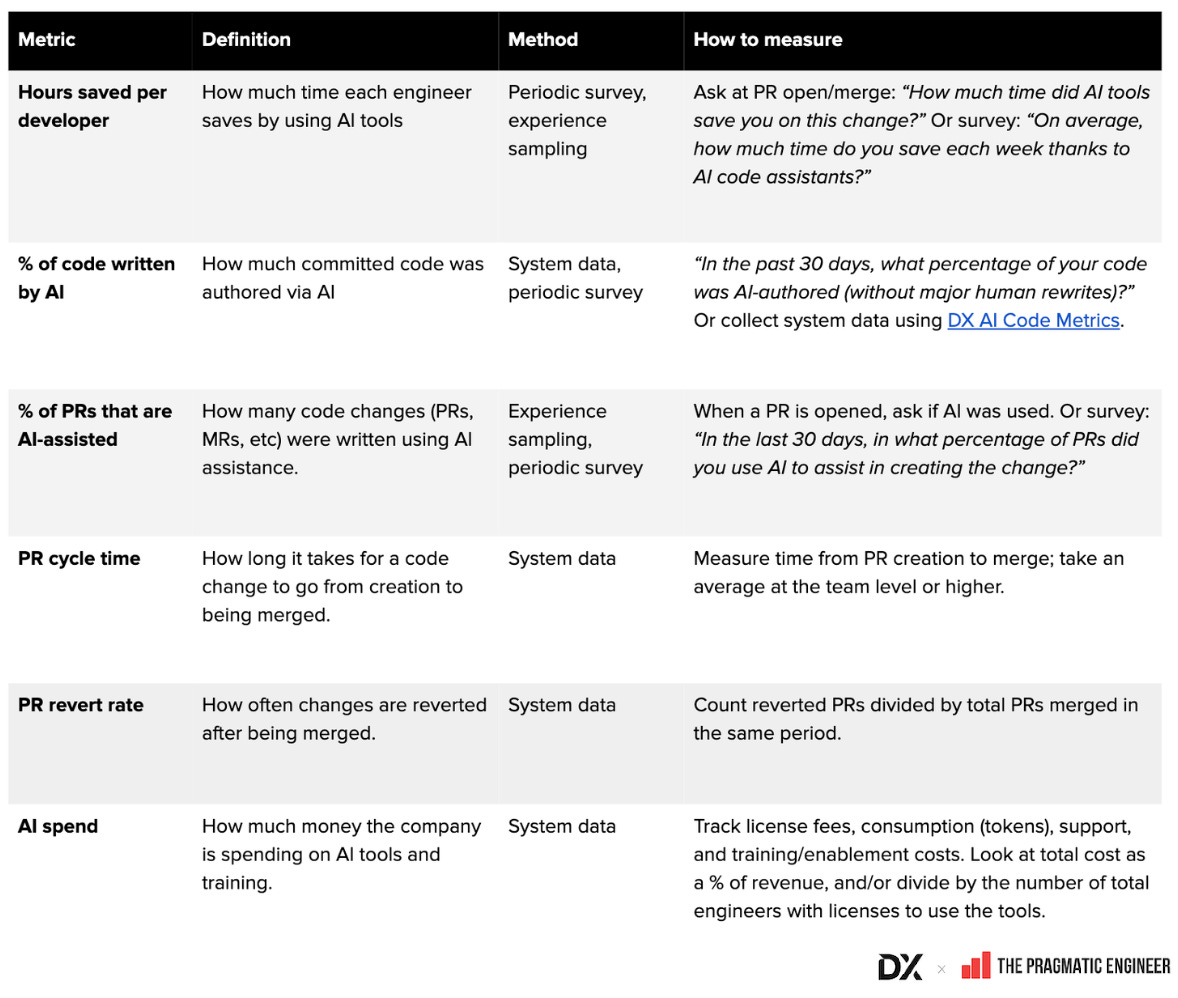
- Glossar gemeinsamer AI-Metriken (Google Sheet): Zusammenstellung von Definitionen, Berechnungsmethoden und Erhebungswegen
- Beispielbilder zu Metriken für AI und Entwicklerproduktivität
- Worauf bei der internen Anwendung zu achten ist
- Es sollte nicht darum gehen, Adoptionsraten oder einer einzelnen Kennzahl hinterherzulaufen, sondern zu prüfen, ob sich die Fähigkeit verbessert, hochwertige Software schnell an Kunden auszuliefern
- Die Schlüsselfrage lautet:
> „Macht AI das, was bereits wichtig ist (Qualität, Release-Geschwindigkeit, Developer Experience), tatsächlich besser?“ - Fragen für Leadership-Meetings:
- Wie definieren wir in unserer Organisation Engineering-Erfolg?
- Liegen uns Leistungsdaten aus der Zeit vor der Einführung von AI-Tools vor? Falls nicht, wie schaffen wir schnell eine Baseline?
- Verwechseln wir AI-Aktivität mit AI-Impact?
- Halten wir die Balance zwischen Geschwindigkeit, Qualität und Wartbarkeit?
- Zeigt sich bereits ein Einfluss auf die Developer Experience?
- Betreiben wir einen mehrschichtigen Messansatz, der sowohl Systemdaten als auch selbstberichtete Daten umfasst?
{kind=link}
{kind=link}
7. Wie Monzo den AI-Impact misst
- Frühe Einführungsphase
- Das erste Tool war GitHub Copilot. Es war in der GitHub-Lizenz enthalten und fügte sich nahtlos in VS Code ein, sodass alle Engineers sofort damit arbeiten konnten.
- Danach wurden verschiedene Tools wie Cursor, Windsurf und Claude Code parallel getestet, während weiterhin vor allem in Copilot investiert wurde.
- Philosophie bei der Bewertung von AI-Tools
- In einem sich schnell wandelnden Tool-Ökosystem ist eigene praktische Erfahrung unverzichtbar.
- Erst wenn Teammitglieder AI täglich auf echten Code anwenden und sogar Agent-Konfigurationsdateien selbst erstellen und nutzen, lässt sich die Leistungsfähigkeit beurteilen.
- Bei der Bewertung werden objektive Kennzahlen (Nutzung, Performance) und subjektive Umfragen (Zufriedenheit mit der DX) parallel genutzt.
- Wirkung und wahrgenommener Nutzen
- Engineers haben das Gefühl, dass AI Dokumentensuche, Zusammenfassungen und Codeverständnis erleichtert und damit die kognitive Belastung reduziert.
- In einem wettbewerbsintensiven Talentmarkt besteht ohne die besten Tools das Risiko, Entwickler zu verlieren → schon die Bereitstellung der Tools ist eine Strategie zur Mitarbeiterbindung.
- Schwierigkeiten bei der Messung
- Die von den Anbietern gelieferten Zahlen bleiben auf begrenzte Kennzahlen wie Akzeptanzraten beschränkt, während der echte Business-Impact schwer zu erfassen ist.
- Auch eine exakte Überprüfung per A/B-Test ist in der Praxis kaum möglich.
- Nutzungsdaten aus verschiedenen Tools (GitHub, Gemini, Slack, Notion usw.) lassen sich nur schwer zusammenführen → Telemetry-Beschränkungen und Vendor Lock-in sind die wichtigsten Hindernisse.
- Deshalb ist derzeit vor allem das subjektive Empfinden der Entwickler das zentrale Signal.
- Bereiche, in denen es gut funktioniert
- Migrationen zeigen große Wirkung: Bei Codeänderungsarbeiten wird eine Reduktion des Aufwands um 40 bis 60 % wahrgenommen.
- Bei repetitiven, manuellen Aufgaben wie dem Kommentieren von Datenmodellen erstellt das LLM einen ersten Entwurf, den Engineers anschließend überarbeiten → erhebliche Arbeitseinsparungen im großen Maßstab.
- Unerwartete Erkenntnisse
- Geringes Bewusstsein für LLM-Kosten: Wer die Abrechnungen mit dem tatsächlichen Token-Verbrauch sieht, würde den Optimierungsbedarf viel deutlicher spüren.
- Beispiel: Automatische Code-Reviews in Copilot verbrauchen viele Tokens und bringen wenig Nutzen, daher sind sie standardmäßig deaktiviert und werden bei Bedarf per Opt-in aktiviert.
- Bereiche, in denen AI nicht eingesetzt wird
- Kundendatenbezogene Bereiche: Weder Rohdaten noch de-identifizierte Daten dürfen mit AI verarbeitet werden.
- In sensiblen Datenbereichen hat die Vermeidung von Datenlecks oberste Priorität.
- Philosophie des Platform-Teams
- Guardrails bereitstellen: eine sichere Nutzungsumgebung schaffen, etwa zum Schutz von Daten.
- Beispiele teilen: Erfolgs- und Misserfolgsfälle sowie Erfahrungen mit Prompts transparent offenlegen.
- Doppelseitigkeit betonen: Sowohl Positives als auch Negatives teilen und so eine ausgewogene Perspektive bewahren.
- An die Grenzen von LLMs erinnern: Darauf hinweisen, dass AI wie Menschen Grenzen hat und daher nicht überschätzt werden sollte.
Fazit und Implikationen
- Die Messung des AI-Impacts ist noch ein sehr neues Feld
- In der Branche gibt es keine „beste Methodik“.
- Selbst Unternehmen mit ähnlicher Größe und Marktposition wie Microsoft und Google verwenden unterschiedliche Kennzahlen.
- Jedes Unternehmen hat seinen eigenen Ansatz und seinen eigenen „Flavor“.
- Widersprüchliche Kennzahlen gleichzeitig zu messen, ist üblich
- Ein typisches Beispiel ist die gleichzeitige Verfolgung von Change Failure Rate (Zuverlässigkeit) und PR-Frequenz (Geschwindigkeit).
- Schnelle Releases sind nur dann sinnvoll, wenn sie die Zuverlässigkeit nicht beeinträchtigen; deshalb müssen beide Achsen ausgewogen gemessen werden.
- Die Messung des Impacts von AI-Tools ist eine ähnlich schwierige Aufgabe wie die Messung von Entwicklerproduktivität
- Die Branche ringt seit mehr als zehn Jahren mit der Messung von Produktivität.
- Keine einzelne Kennzahl kann die Produktivität eines Teams erklären, und die Optimierung auf eine bestimmte Metrik erhöht die tatsächliche Produktivität nicht automatisch.
- McKinsey erklärte 2023, das Problem der Produktivitätsmessung „gelöst“ zu haben, doch Kent Beck und der Autor vertreten dazu eine skeptische Position → Gegenartikel
- Es gibt noch keine klare Lösung, aber Experimente sind notwendig
- Solange die Messung von Produktivität nicht vollständig gelöst ist, wird sich auch die Messung des Impacts von AI-Tools kaum vollständig lösen lassen.
- Trotzdem muss weiter experimentiert und mit neuen Ansätzen gearbeitet werden, um die Frage zu beantworten: „Wie verändern AI-Coding-Tools die tägliche und monatliche Effizienz von Einzelpersonen, Teams und Unternehmen?“
Noch keine Kommentare.